About the Project
Flight Prices Prediction is a B.Tech project under Dr Vivek Vijay at IIT Jodhpur
Optimal timing for airline ticket purchasing from the consumer’s perspective is challenging principally because buyers have insufficient information for reasoning about future price movements. In this project we simulate various models for computing expected future prices and classifying whether this is the best time to buy the ticket.
Why this Project?
Anyone who has booked a flight ticket knows how unexpectedly the prices vary. Airlines use using sophisticated quasi-academic tactics which they call "revenue management" or "yield management". The cheapest available ticket on a given flight gets more and less expensive over time. This usually happens as an attempt to maximize revenue based on -
- Time of purchase patterns (making sure last-minute purchases are expensive)
- Keeping the flight as full as they want it (raising prices on a flight which is filling up in order to reduce sales and hold back inventory for those expensive last-minute expensive purchases)
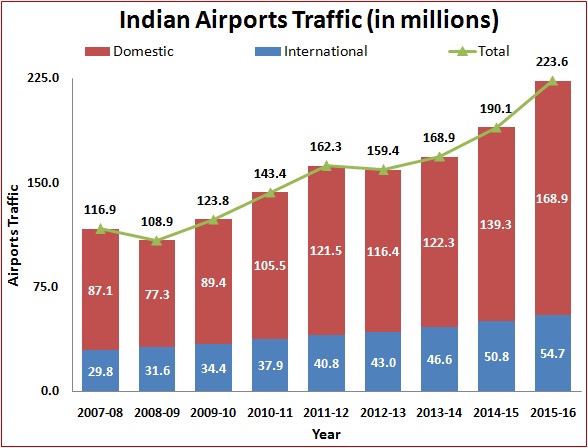
Problem Validation & Market Research
According to a report, India’s civil aviation industry is on a high-growth trajectory. India aims to become the third-largest aviation market by 2020 and the largest by 2030. Indian domestic air traffic is expected to cross 100 million passengers by FY2017, compared to 81 million passengers in 2015, as per Centre for Asia Pacific Aviation (CAPA).
According to Google Trends, the search term - "Cheap Air Tickets" is most searched in India. Moreover, as the middle-class of India is exposed to air travel, consumers hunting for cheap prices increases.
Technical Aspects
The project is basically machine learning & statistic intensive. We used Python & R for the implementation of the models & automation.
-
Automated Script to Collect Historical Data
For any prediction/classification problem, we need historical data to work with. In this project, past flight prices for each route collected on a daily basis is needed. Manually collecting data daily is not efficient and thus a python script was run on a remote server which collected prices daily at specfic time.
-
Cleaning & Preparing Data
After we have the data, we need to clean & prepare the data according to the model's requirements. In any machine learning problem, this is the step that is the most important and the most time consuming. We used various statistical techniques & logics and implemented them using built-in R packages.
-
Analysing & Building Models
Data preparation is followed by analysing the data, uncovering hidden trends and then applying various predictive & classification models on the training set.
-
Merging Models & Accuracy Calculation
Having built various models, we now have to test the models on our testing set and come up with the most suitable metric to calculate the accuracy. Moreover, many a times, merging models and predicting a cummulative target variable proves to be more accurate.