Clustering and Polarity Score
Every product have multiple reviews and hence will have a good number of aspect-modifier pairs. We also found different words used for a very similar aspect of the product. And therefore it becomes very important to group similar aspects into one cluster and thus providing a better accumulated insight of the product. Post clustering, polarity scores of the modifier were averaged out for every cluster to give a quantifiable explaination to opinion.
Word Vectors and Clustering
The first time I was introduced to the concept of word vectors, I remember how amazed I was. Word vectors are a way of defining every word in terms of a bunch of numbers or vectors. This way of defining vectors corresponding to each word makes modelling relationships very intutive. For instance, in our case to find similar words, a simple distance function will signify how different or similar two words are. Using this very concept, we apply clustering on the word vectors of the extracted aspects. You can read more about word vectors here
The most famous implementation of words vectors is the word2vec project. However in our case, we used spaCy for vectorization as it provides fast and easy access to over a million unique word vectors, and its multi-task CNN model is trained on 'web' data and not 'newspaper' data as in other libraries like NLTK.
The word vectors were then grouped using K-Means clustering algorithm in Scikit-Learn. We experimented with other clustering algorithms such as DBSCAN. However, K-Means gave us optimal results with four clusters. The clusters were labeled based on the most frequently appearing word in each cluster.
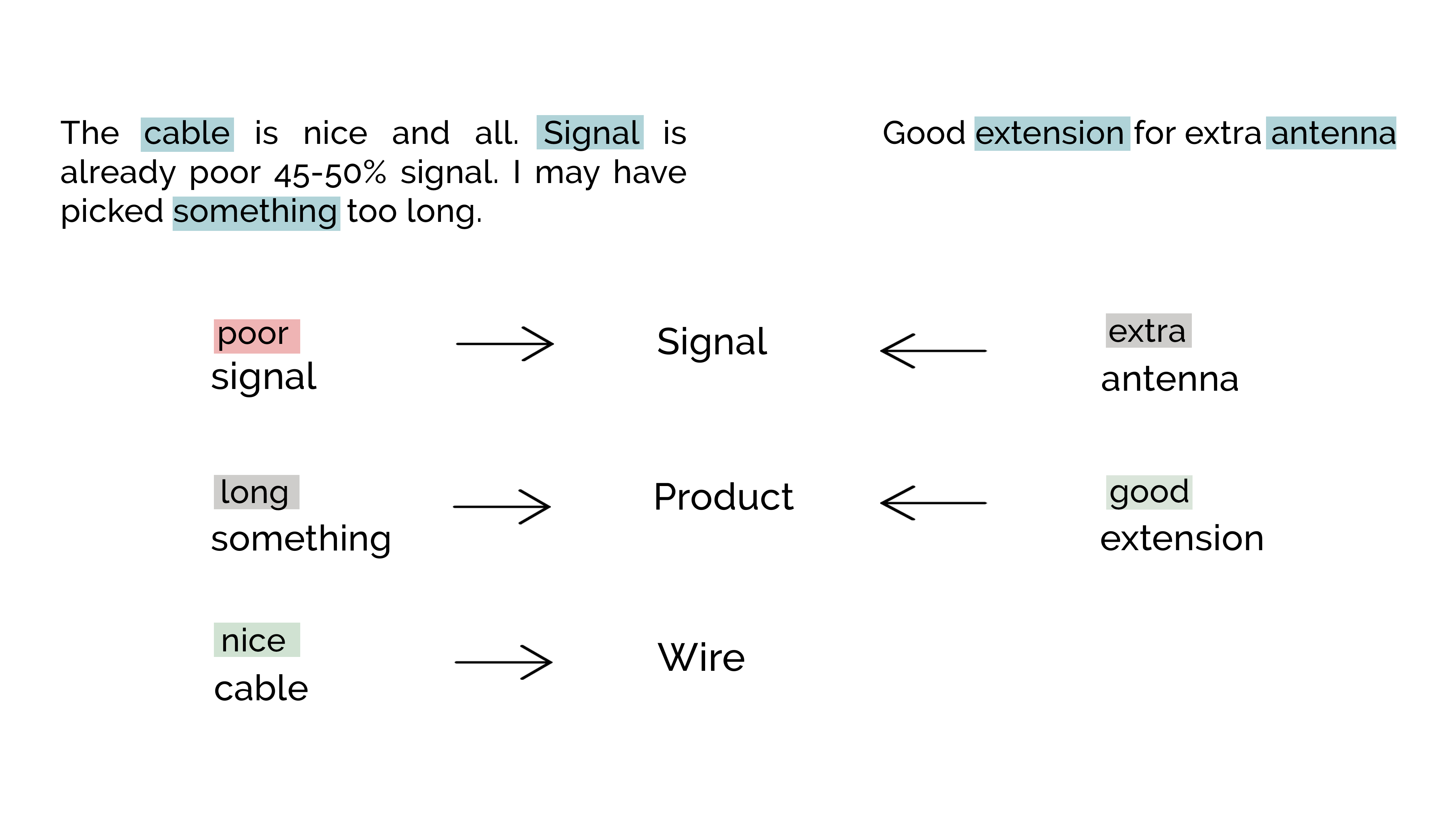
The above figure captures how this process works using two sample reviews. The words in the middle are the cluster names. Do note that the cluster names are formed using more than two reviews. We have shown just two reviews here as samples.
Polarity : The goods and the bads
To determine polarity of the aspects, we used the VADER Sentiment Analysis tool which is part of the NLTK library. We chose this over other tools such as spaCy and TextBlob because of the accuracy and speed.
The polarity metric worked well for unambiguous positive or negative words; however, for some equivocal adjectives which require context for interpretation, the metric did not give an accurate value. A more contextual approach would make more sense in this case.
Database : Integrating into the pipeline
A parallel challenge to every piece of the project was scaling for the huge data we were handling. To make it easier for the UI to pull data and ensure that it's easier to keep updating the model results in future as we run it on more data, we hosted our model results on a Microsoft SQL Server database.
We are hosting the database on AWS to store the product, review, aspect and cluster data, and aggregate the polarity. Based on the results obtained from the model, we imported data into the database using Sequelize. A Node.js server was set up in the AWS machine which accepts requests with the product ID, and returns the query results needed for the visualizations.
One can find the whole codebase on the github repository.