Aspect Extraction
The objective of this step was to extract instances of product aspects and modifiers that express the opinion about a particular aspect. We used the dependency parser tree in Python's spaCy package to extract pairs of words based on specific syntactic dependency paths. The output of this step was a list of such noun-adjective which serve as the input to the next step of grouping aspects.
Why dependency parser?
There are two basic school of thoughts in the statistical analysis of languages - context free grammar & dependency grammar. The former assumes no underlying relationship and rules between words while the latter assumes a very intricate logic behind any language. I personally found this lecture by Professor Chris Manning particularly insightful to understand the difference between the two.
Now to understand why we decided to go ahead with dependency grammar in this project, it becomes very important to know what we are trying to achieve. Look at the sentence below -
The delivery was very late!
In layman's term, we want the model to extract (delivery,late) as the aspect-modifier pair. Looking at it closely, these words are basically noun & adjective pairs. And hence, there exists an underlying relationship and meaning behind these words that we can exploit using the dependency parsing tree by curating custom rules.
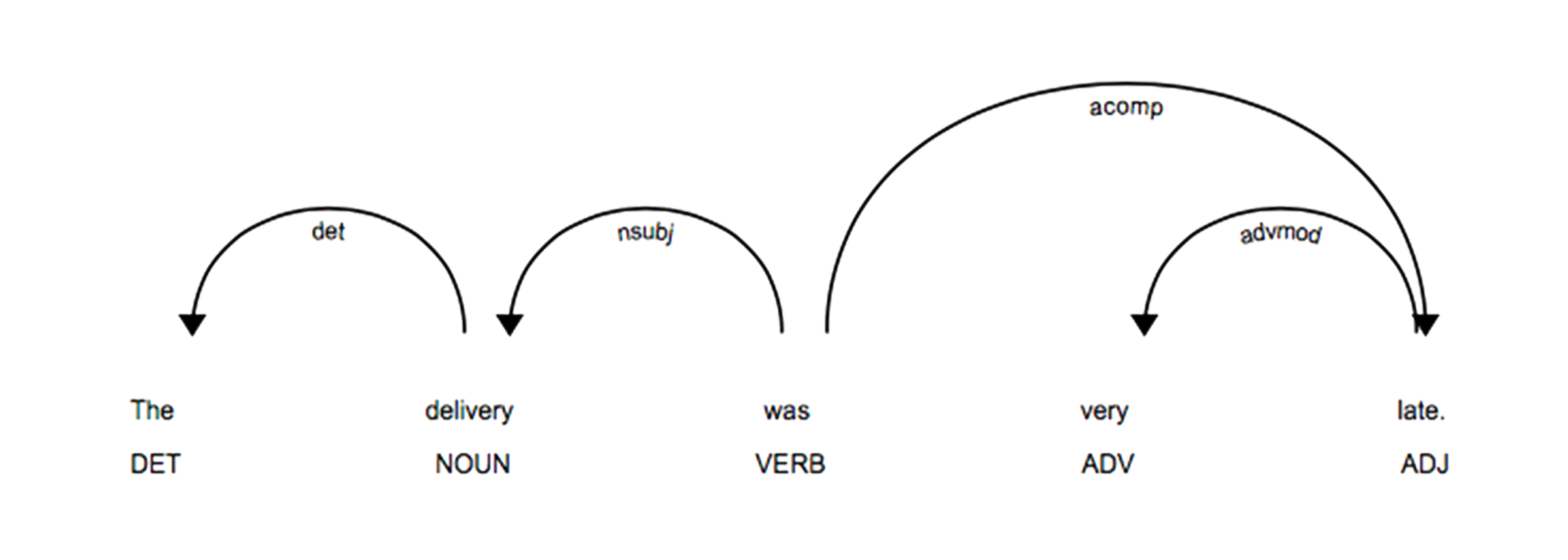
Figure: Dependency parsing tree from spaCy package
Deep dive into custom dependency rules
The dependency parsing tree as modelled by the spaCy package can be seen in the above figure. Using such a tree, we curated a bunch of rules by manually reading through 100-150 reviews so we can extract aspect-modifier pairs from the reviews.
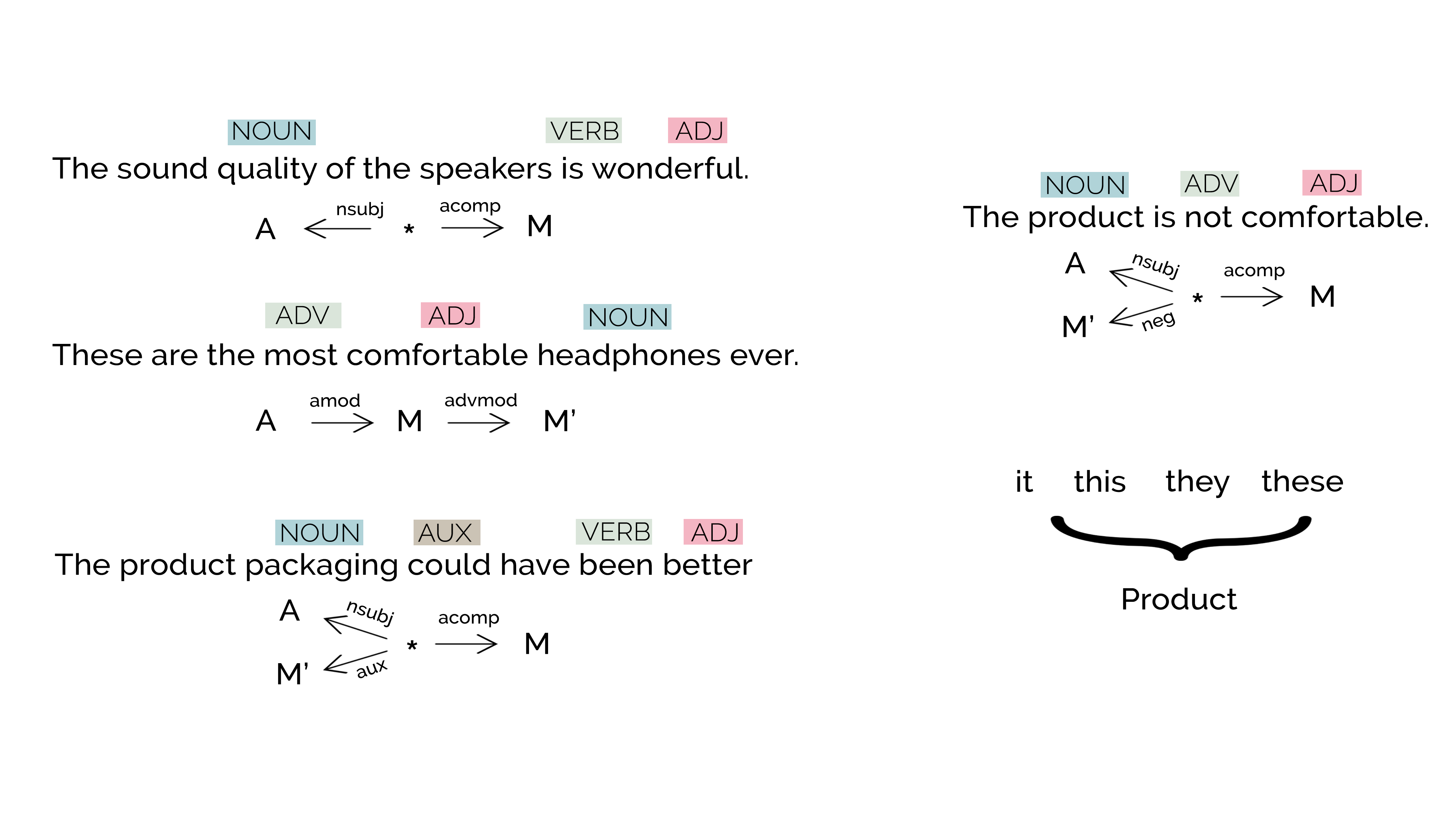
Some of the curated rules can be seen in the figure above. I have explained a couple of them in detail here -
- A word with
nsubjdependency relationship with a verb token would be the noun of the phrase, and a word withacompdependency relationship would be the adjective of this noun. Thus, we would extract this pair as a relevant aspect-modifier pair. (Note : To know more about these dependency identifiers, visit Universal Dependencies) - In order to incorporate negatives, we check if there is any word with a
negrelationship. If yes, we append it to the already found modifier. - We also noticed the usage of pronouns like
it,this,they & theseas a replacement to the product under review. And hence we replaced these words withproductkey word.
To be very explicit, as per the notations used in the image, we get an output (A, M + M') as the pair
Integrating into the pipeline
Having understood how parsing rules were used to solve the problem at hand, now we see how we scaled the algorithm to incorporate it into the data pipeline.
Python's spaCy package was used to implement these rules using the POS tags provided by the package. Each review was passed through this model and the output was appended in the form of a json file, where along with the aspect-modifier pairs, important meta data of the review like review_id, product_id and product_category were also appended.
One can find the whole codebase on the github repository along with a sample output file.